MMH-Badger MAC
In cryptography, to guarantee the integrity of a message, one can use either public key digital signatures or use a Message Authentication Code (MAC). A MAC is one of the possible authentication techniques involving the use of a secret key to generate a small fixed-size block of data. The basic setting of MAC is as follows. Two parties A and B want to communicate by sending a message 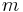 . They share a secret key
. They share a secret key  . When A sends a message to B then A calculates the MAC as a function of the message and the key
. When A sends a message to B then A calculates the MAC as a function of the message and the key 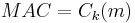 . The message and the key are sent to B. Then B uses the same secret key and calculates the MAC on the received message. The received MAC is compared to the new MAC. When it matches then the message is authentic because only the receiver and the sender know the secret key.
. The message and the key are sent to B. Then B uses the same secret key and calculates the MAC on the received message. The received MAC is compared to the new MAC. When it matches then the message is authentic because only the receiver and the sender know the secret key.
Contents |
Introduction
Carter and Wegman[1] introduced universal hashing to construct a message authentication codes (MACs). Universal hashing is used to build secure message authentication schemes where the opponent’s ability to fake messages is bounded by the collision probability of the hash family. Proposals such as UMAC, CRC32, BOB, Poly1305-AES, and IPSX deal with implementation of universal hashing as a tool for achieving fast and secure message authentication. This page discusses MMH[2] and Badger.[3]
Universal hash function families[2][3]
Universal hashing was first introduced by Carter and Wegman in 1979 and was studied further by Sarwate, Wegman and Carter and Stinson.[4] Universal hashing has many important applications in theoretical computer science and was used by Wegman and Carter in the construction of message authentication codes (MACs) in.[1] Universal hashing can be defined as a mapping from a finite set A with size a to a finite set B with size b.[5]
The following sections define properties a universal hash function should satisfy.
ϵ-almost ∆-universal (ϵ-A∆U)
Let 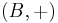 be an Abelian group. A family H of hash functions that maps from a set A to B is said to be ϵ-almost ∆-universal (ϵ-A∆U) w.r.t. , if for any distinct elements
be an Abelian group. A family H of hash functions that maps from a set A to B is said to be ϵ-almost ∆-universal (ϵ-A∆U) w.r.t. , if for any distinct elements 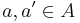 and for all
and for all 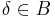 :
:
![{\Pr}_{h \in H}[h(a)-h(a')=\delta] \le \epsilon](/2012-wikipedia_en_all_nopic_01_2012/I/f5d425eca582051b41bba1c56f73569d.png)
H is ∆-universal (∆U) if 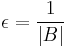 .
.
ϵ-almost universal family or (ϵ-AU) family
An ϵ-almost universal family or (ϵ-AU) family is one type of family in the universal hash function. This property is defined as follows:
Let ϵ be any positive real number. An ϵ-almost universal (ϵ-AU) family H of hash functions mapping from a set A to B is a family of functions from A to B, such that for any distinct elements :
![{\Pr}_{h \in H}[h(a)=h(a')] \le \epsilon](/2012-wikipedia_en_all_nopic_01_2012/I/a1af8096e828126847dd7f54295d2ab2.png)
H is universal (U) if .
The definition above states that the probability of a collision is at most ϵ for any two distinct inputs.
ϵ-almost strongly-universal family or (ϵ-ASU)family
An ϵ-almost strongly universal family or (ϵ-ASU)family is one type of family in the universal hash function defined as follows:
Let ϵ be any positive real number. An ϵ-almost strongly-universal (ϵ-ASU) family H of Hash functions maps from a set A to B is a family of functions from A to B, such that for any distinct elements and all 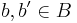 :
:
![{\Pr}_{h \in H}[h(a)=b] = \frac {1}{\left\vert B \right\vert}](/2012-wikipedia_en_all_nopic_01_2012/I/62d125ad873caebea3b9e3e274a56102.png)
and
![{\Pr}_{h \in H}[h(a)=b, h(a')=b'] = \frac {\epsilon}{\left\vert B \right\vert}](/2012-wikipedia_en_all_nopic_01_2012/I/fd2fcfa63aab0a317b24afa427023e41.png)
H is strongly universal (SU) if .
The first condition states that the probability that a given input a is mapped to a given output b equals 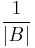 . The second condition implies that if a is mapped to b, then the conditional probability that
. The second condition implies that if a is mapped to b, then the conditional probability that 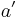 with
with 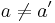 is mapped to
is mapped to 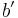 is upper bounded by ϵ.
is upper bounded by ϵ.
MMH (Multilinear Modular Hashing)
The name MMH stands for Multilinear-Modular-Hashing. Applications in Multimedia are for example to verify the integrity of an on-line multimedia title. The performance of MMH is based on the improved support of integer scalar-products in modern microprocessors.
MMH uses single precision scalar-products as its most basic operation. It consists of a (modified) inner product between the message and a key modulo a prime 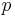 . The construction of MMH works in the finite field
. The construction of MMH works in the finite field 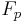 for some prime integer .
for some prime integer .
MMH*
MMH* involves a construction of a family of hash functions consisting of multilinear functions on 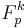 for some positive integer . The family MMH* of functions from to is defined as follows.
for some positive integer . The family MMH* of functions from to is defined as follows.
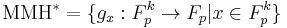
where x, m are vectors, and the functions 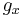 are defined as follows.
are defined as follows.
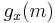 =
= 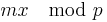 =
= 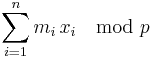
In the case of MAC, is a message and  is a key where
is a key where 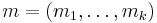 and
and 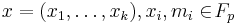 .
.
MMH* should satisfy the security requirements of a MAC, enabling say Ana and Bob to communicate in an authenticated way. They have a secret key . Say Charles listens to the conversation between Ana and Bob and wants to change the message into his own message to Bob which should pass as a message from Ana. So, his message 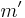 and Ana's message will differ in at least one bit (eg.
and Ana's message will differ in at least one bit (eg. 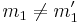 ).
).
Assume that Charles knows that the function is of the form 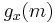 and he knows Ana's message but he does not know the key x then the probability that Charles can change the message or send his own message can be explained by the following theorem.
and he knows Ana's message but he does not know the key x then the probability that Charles can change the message or send his own message can be explained by the following theorem.
Theorem 1[2]:The family MMH* is ∆-universal.
Proof:
Take 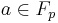 , and let
, and let 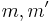 be two different messages. Assume without loss of generality that . Then for any choice of
be two different messages. Assume without loss of generality that . Then for any choice of 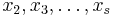 , there is
, there is
![\begin{align}
{\Pr}_{x_1}[g_x (m)-g_x (m')\equiv a \mod p] &= {\Pr}_{x_1}[(m_1 x_1%2Bm_2 x_2%2B \cdots %2Bm_k x_k )-(m'_1 x_1%2Bm'_2 x_2%2B\cdots%2Bm'_k x_k )\equiv a \mod p]\\
&= {\Pr}_{x_1}[(m_1-m'_1)x_1%2B(m_2-m'_2)x_2%2B \cdots %2B(m_k-m'_k)x_k]\equiv a \mod p]\\
&= {\Pr}_{x_1}[(m_1-m'_1)x_1%2B\textstyle \sum_{k=2}^s(m_k-m'_k)x_k\equiv a \mod p]\\
&= {\Pr}_{x_1}[(m_1-m'_1)x_1\equiv a - \textstyle \sum_{k=2}^s(m_k-m'_k)x_k \mod p]\\
&=\frac {1}{p}
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/f1def27cf1da0f60c19cf56f5857fea4.png)
To explain the theorem above, take for prime represent the field as 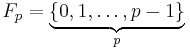 . If one takes an element in , let say
. If one takes an element in , let say 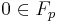 then the probability that
then the probability that 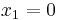 is
is
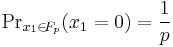
So, what one actually needs to compute is
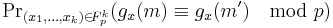
But,
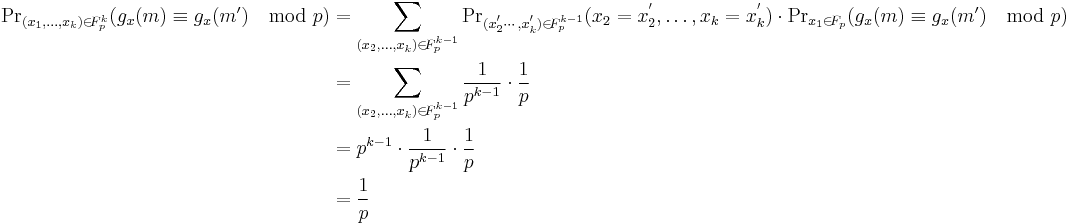
From the proof above, 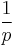 is the collision probability of the attacker in 1 round, so on average verification queries will suffice to get one message accepted. To reduce the collision probability, it is necessary to choose large p or to concatenate
is the collision probability of the attacker in 1 round, so on average verification queries will suffice to get one message accepted. To reduce the collision probability, it is necessary to choose large p or to concatenate  such MACs using independent keys so that the collision probability becomes
such MACs using independent keys so that the collision probability becomes 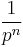 . In this case the number of keys are increased by a factor of and the output is also increased by .
. In this case the number of keys are increased by a factor of and the output is also increased by .
Halevi and Krawczyk[2] construct a variant called 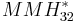 . The construction works with 32-bit integers and with the prime integer
. The construction works with 32-bit integers and with the prime integer 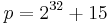 . Actually the prime p can be chosen to be any prime which satisfies
. Actually the prime p can be chosen to be any prime which satisfies 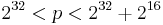 . This idea is adopted from the suggestion by Carter and Wegman to use the primes
. This idea is adopted from the suggestion by Carter and Wegman to use the primes 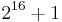 or
or 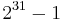 .
.
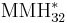 is defined as follows:
is defined as follows:
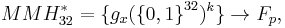
where 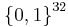 means
means 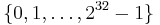 (i.e., binary representation)
(i.e., binary representation)
The functions are defined as follows.
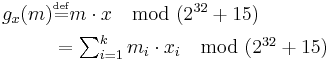
where
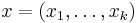 ,
, 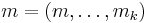
By theorem 1, the collision probability is about ϵ = 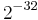 , and the family of can be defined as ϵ-almost ∆ Universal with ϵ = .
, and the family of can be defined as ϵ-almost ∆ Universal with ϵ = .
The value of k
The value of k that describes the length of the message and key vectors has several effects:
- Since the costly modular reduction over k is multiply and add operations increasing k should decrease the speed.
- Since the key x consist of k 32-bit integers increasing k will results in a longer key.
- The probability of breaking the system is
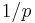 and
and 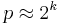 so increasing k makes the system harder to break.
so increasing k makes the system harder to break.
Performance
Below are the timing results for various implementations of MMH[2] in 1997, designed by Halevi and Krawczyk.
- A 150 Mhz PowerPC 604 RISC machine running AIX
| 150 MHz PowerPC 604 | Message in Memory | Message in Cache |
|---|---|---|
| 64-bit | 390 Mbit/second | 417 Mbit/second |
| 32-bit output | 597 Mbit/second | 820 Mbit/second |
- A 150 MHz Pentium-Pro machine running Windows NT
| 150 MHz PowerPC 604 | Message in Memory | Message in Cache |
|---|---|---|
| 64-bit | 296 Mbit/second | 356 Mbit/second |
| 32-bit output | 556 Mbit/second | 813 Mbit/second |
- A 200 MHz Pentium-Pro machine running Linux
| 150 MHz PowerPC 604 | Message in Memory | Message in Cache |
|---|---|---|
| 64-bit | 380 Mbit/second | 500 Mbit/second |
| 32-bit output | 645 Mbit/second | 1080 Mbit/second |
Badger
Badger is a Message Authentication Code (MAC) based on the idea of universal hashing and was developed by Boesgaard, Christensen, and Zenner.[3] It is constructed by strengthening the ∆-universal hash family MMH using an ϵ-almost strongly universal (ASU) hash function family after the application of ENH (see below), where the value of ϵ is 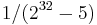 .[6] Since Badger is a MAC function based on the universal hash function approach, the conditions needed for the security of Badger are the same as those for other universal hash functions such as UMAC.
.[6] Since Badger is a MAC function based on the universal hash function approach, the conditions needed for the security of Badger are the same as those for other universal hash functions such as UMAC.
The Badger MAC processes a message of length up to 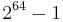 bits and returns an authentication tag of length
bits and returns an authentication tag of length 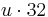 bits, where
bits, where 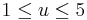 . According to the security needs, user can choose the value of
. According to the security needs, user can choose the value of 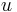 , that is the number of parallel hash trees in Badger. One can choose larger values of u, but those values do not influence further the security of MAC. The algorithm uses a 128-bit key and the limited message length to be processed under this key is
, that is the number of parallel hash trees in Badger. One can choose larger values of u, but those values do not influence further the security of MAC. The algorithm uses a 128-bit key and the limited message length to be processed under this key is 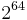 .[7]
.[7]
The key setup has to be run only once per key in order to run the Badger algorithm under a given key, since the resulting internal state of the MAC can be saved to be used with any other message that will be processed later.
ENH
Hash families can be combined in order to obtain new hash families. For the ϵ-AU, ϵ-A∆U, and ϵ-ASU families, the latter are contained in the former. For instance, an A∆U family is also an AU family, an ASU is also an A∆U family, and so forth. On the other hand, a stronger family can be reduced to a weaker one, as long as a performance gain can be reached. A method to reduce ∆-universal hash function to universal hash functions will be described in the following.
Theorem 2[3]
Let 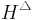 be an ϵ-AΔU hash family from a set A to a set B. Consider a message
be an ϵ-AΔU hash family from a set A to a set B. Consider a message 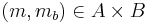 . Then the family H consisting of the functions
. Then the family H consisting of the functions 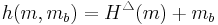 is ϵ-AU.
is ϵ-AU.
If 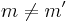 , then the probability that
, then the probability that 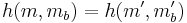 is at most ϵ, since is an ϵ-A∆U family. If
is at most ϵ, since is an ϵ-A∆U family. If 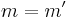 but
but 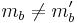 , then the probability is trivially 0. The proof for Theorem 2 was described in [3]
, then the probability is trivially 0. The proof for Theorem 2 was described in [3]
The ENH-family is constructed based on the universal hash family NH (which is also used in UMAC):
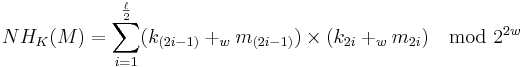
Where ‘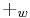 ’ means ‘addition modulo
’ means ‘addition modulo 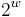 ’, and
’, and 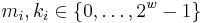 . It is a
. It is a 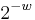 -A∆U hash family.
-A∆U hash family.
Lemma 1[3]
The following version of NH is -A∆U:
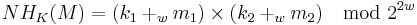
Choosing w=32 and applying Theorem 1, one can obtain the -AU function family ENH, which will be the basic building block of the badger MAC:
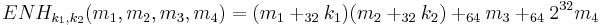
where all arguments are 32-bits long and the output has 64-bits.
Construction
Badger is constructed using the strongly universality hash family and can be described as
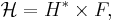
where an 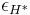 -AU universal function family H* is used to hash messages of any size onto a fixed size and an
-AU universal function family H* is used to hash messages of any size onto a fixed size and an 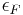 -ASU function family F is used to guarantee the strong universality of the overall construction. NH and ENH are used to construct H*. The maximum input size of the function family H* is and the output size is 128 bits, split into 64 bits each for the message and the hash. The collsion probability for the H*-function ranges from to
-ASU function family F is used to guarantee the strong universality of the overall construction. NH and ENH are used to construct H*. The maximum input size of the function family H* is and the output size is 128 bits, split into 64 bits each for the message and the hash. The collsion probability for the H*-function ranges from to 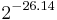 . To construct the strongly universal function family F, the ∆-universal hash family MMH* is transformed into a strongly universal hash family by adding an additional key.
. To construct the strongly universal function family F, the ∆-universal hash family MMH* is transformed into a strongly universal hash family by adding an additional key.
Two steps on Badger
There are two steps that have to be executed for every message: processing phase and finalize phase.
Processing phase[7] In this phase, the data is hashed to a 64-bit string. A core function 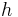 :
: 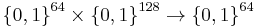 is used in this processing phase, that hashes a 128-bit string
is used in this processing phase, that hashes a 128-bit string 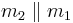 to a 64-bit string
to a 64-bit string 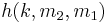 as follows:
as follows:
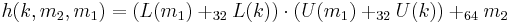
for any n, 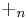 means addition modulo
means addition modulo 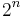 . Given a 2n-bit string x, L(x) means least significant n bits, and U(x) means most significant n bits.
. Given a 2n-bit string x, L(x) means least significant n bits, and U(x) means most significant n bits.
A message can be processed by using this function. Denote level_key [j][i] by 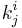 .
.
Pseudo-code of the processing phase is as follow.
L=|M|
if L=0
M^1=⋯=M^u=0
Go to finalization
r=L mod 64
if r≠0:
M=0^(64-r)∥M
for i=1 to u:
M^i=M
v^'=max{1,⌈log_2 L⌉-6}
for j=1 to v^':
divide M^i into 64-bit blocks, M^i=m_t^i∥⋯∥m_1^i
if t is even:
M^i=h(k_j^i,m_t^i,m_(t-1)^i )∥⋯∥h(k_j^i,m_2^i,m_1^i )
else
M^i=m_t^i∥h(k_j^i,m_(t-1)^i,m_(t-2)^i )∥⋯∥h(k_j^i,m_2^i,m_1^i )
Finalize phase[7] In this phase, the 64-string resulting from the processing phase is transformed into the desired MAC tag. This finalization phase uses the Rabbit stream cipher and uses both key setup and IV setup by taking the finalization key final_key[j][i] as .
Pseudo-code of the finalization phase
RabbitKeySetup(K) RabbitIVSetup(N) for i=1 to u: Q^i=0^7∥L∥M^i divide Q^i into 27-bit blocks, Q^i=q_5^i∥⋯∥q_1^i S^i=(∑_(j=1)^5 (q_j^i K_j^i))+K_6^i mod p S=S^u∥⋯∥S^1 S=S ⨁ RabbitNextbit(u∙32) return S
Notation:
From the pseudocode above, k denotes the key in the Rabbit Key Setup(K) which initializes Rabbit with the 128-bit key k. M denotes the message to be hashed and |M| denotes the length of the message in bits. q_i denotes a message M that is divided into i blocks. For the given 2n-bit string x then L(x) and U(x) respectively denoted its least significant n bits and most significant n bits.
Performance
Boesgard, Christensen and Zenner report the performance of Badger measured on a 1.0 GHz Pentium III and on a 1.7 Ghz Pentium 4 processor.[3] The speed-optimized versions were programmed in assembly language inlined in C and compiled using the Intel C++ 7.1 compiler.
The following table presents Badger's properties for various restricted message lengths. “Memory req.” denotes the amount of memory required to store the internal state including key material and the inner state of the Rabbit stream cipher . “Setup” denotes the key setup, and “Fin.” denotes finalization with IV-setup.
| Max. Message Size | Forgery Bound | Memory Reg. | Setup Pentium III | Fin. Pentium III | Setup Pentium III | Fin. Pentium III |
|---|---|---|---|---|---|---|
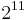 bytes (e.g.IPsec) bytes (e.g.IPsec) |
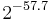 |
400 bytes | 1133 cycles | 409 cycles | 1774 cycles | 776 cycles |
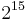 bytes (e.g.TLS) bytes (e.g.TLS) |
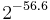 |
528 bytes | 1370 cycles | 421 cycles | 2100 cycles | 778 cycles |
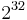 bytes bytes |
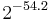 |
1072 bytes | 2376 cycles | 421 cycles | 3488 cycles | 778 cycles |
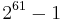 bytes bytes |
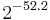 |
2000 bytes | 4093 cycles | 433 cycles | 5854 cycles | 800 cycles |
See also
External links
References
- ^ a b Carter, Larry; Wegman, Mark N (1981). "New hash functions and their use in authentication and set equality". http://www.sciencedirect.com/science?_ob=ArticleURL&_udi=B6WJ0-4B55KFD-1M&_user=10&_coverDate=06%2F30%2F1981&_rdoc=1&_fmt=high&_orig=search&_origin=search&_sort=d&_docanchor=&view=c&_searchStrId=1618778289&_rerunOrigin=scholar.google&_acct=C000050221&_version=1&_urlVersion=0&_userid=10&md5=782364a1012dd3c9f2ebd8aff12a2647&searchtype=a.
- ^ a b c d e Halevi, Shai; Krawczyk, Hugo (1997). "MMH:Software Message Authentication in the Gbit/second rates". http://www.springerlink.com/content/l650p46118v0188g/.
- ^ a b c d e f g h Boesgaard, Martin; Scavenius, Ove; Pedersen, Thomas; Christensen, Thomas; Zenner, Eric (2005). "Badger- A fast and provably secure MAC". http://www.erikzenner.name/docs/2005_badger.pdf.
- ^ Stinson, Douglas R. (2003). "Universal hashing and authentication code". http://www.cacr.math.uwaterloo.ca/~dstinson/papers/hashingdcc.ps.
- ^ Nevelsteen, Wim; Preneel, Bart (1999). "Software Performance of Universal Hash Functions". https://www.cosic.esat.kuleuven.be/publications/article-73.pdf.
- ^ Lucks, Stefan; Rijmen, Vincent (2005). "Evaluation of Badger". http://www.cryptico.com/Files/Filer/Badger_Security_Report.pdf.
- ^ a b c "Badger Message Authentication Code,Algorithm Specification". 2005. http://www.cryptico.com/Files/Filer/WP_Badger_Specification.pdf.